
Overview
We all know that smart speakers and their associated virtual assistants are a smashing success. From March 2018, data from Voicebot.ai indicates that nearly 20% of US adults have access to a smart speaker; which translates into more than 47 million smart speaker users in the US alone. More recent research from Adobe Analytics predicts that by the end of 2018, almost 50% of consumers will own a smart speaker. This hot product category shows no signs of slowing down and the competition is quickly heating up. However, voice first devices face some headwinds and unique challenges which must be addressed before they can become as omnipresent as the internet or mobile phones. One of those challenges is the recognition of accented speech.
With thousands of languages and dialects across the world, addressing accented speech can seem an unsurmountable task. Where do we start? Vocalize.ai decided to start with foreign-born residents living in the US. According to the United Nations and US Census bureau, foreign-born residents compromise just over 15% of the US population with the fastest growing segments being people from China and India. Based on that data, Vocalize.ai created three datasets to support an evaluation of Google, Alexa and Siri performance with accented speech. Each dataset consists of recorded speech by a voiceover professional, who was born in the country of the associated accent. The datasets include:
- English with US accent
- English with Indian accent
- English with Chinese accent
The results reported here are by no means all inclusive, the work is ongoing and there is much to do. Rather, this is meant as continuation of the ongoing conversation about the voice-first future. Having said that, these results do clearly demonstrate strengths and weaknesses with different smart speaker solutions. **Spoiler Alert**Our results indicate that one company is taking the early lead when dealing with accented speech.
Approach
The primary function of every smart speaker is to hear what we say; simply defined as access to acoustic information. For a smart speaker this task is handled by the wake word and speech recognition engines. Accurate hearing is paramount so the system can proceed to understand and successfully process the user’s request. So, our focus for this round of smart speaker evaluations is all about hearing. Hearing words, hearing sentences, hearing in a quiet room, hearing in a noisy room and most importantly, hearing accented speech.
To assess the hearing capabilities of smart speakers, Vocalize.ai leverages test protocols from the field of audiology; the science and study of human hearing. The basic premise is that we want virtual assistants that hear as well as we do. Since childhood we have all been learning the conversational skills of hearing and speaking for effective communication. We carry these preprogrammed expectations with us when conversing with smart speakers or virtual assistants. To accommodate human conversational expectations, Vocalize.ai evaluates smart speaker hearing capabilities with the same procedures used to assess human hearing. For this accented speech evaluation, we are applying the following protocols:
- Isolated Word Recognition
- Speech Recognition Threshold
- Speech In Noise
Results
Isolated Word Recognition (IWR)
Each smart speaker is presented with 36 spondaic words at a distance of 1 meter and a level of 50dB SPL. The environment is a sound isolated room with background noise less than 30dBA. The task is for the smart speaker to successfully recognize the words in these optimal listening conditions. The complete procedure is repeated for each dataset. The percentage score indicates the number of words correctly recognized (i.e. higher score is better).
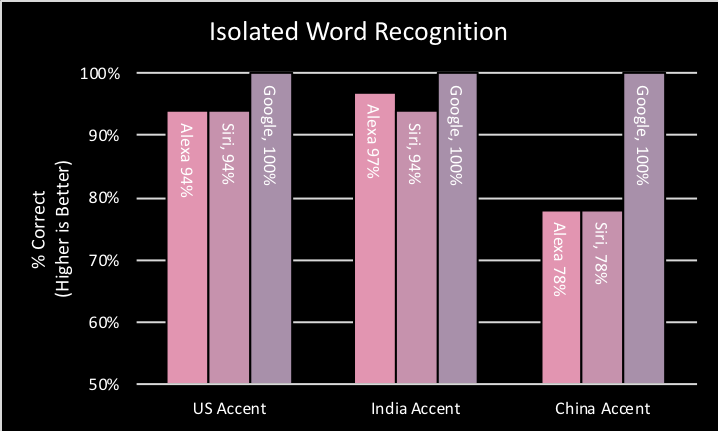
IWR Observations
Google, Alexa and Siri all performed very well with both US-accent and India-accent. Each scoring within the 94% to 100% range. However, when presented with China-accent, both Alexa and Siri showed a significant drop in performance. Alexa and Siri both scored 78%, a clear indication that people speaking English with a Chinese accent may have to make an extra effort to carefully annunciate each word. Google maintained a perfect 100% score across each accent and no degradation related to accent could be detected.
Speech Recognition Threshold (SRT)
Spondaic words are presented at decreasing volume levels per the American Speech Hearing Association (ASHA.org) guidelines; determining threshold levels for detecting and recognizing speech. The result in dB SPL represents the sound pressure level at 1 meter for which the system correctly recognizes 50% of the speech. Only words which have been previously recognized in the IWR test were used. To compare how accent affects the system performance, we look at the maximum range in threshold scores using the US-accent benchmark. A smaller range indicates less impact on successfully detecting speech. A larger range indicates that users with accented speech will need to speak louder to be successfully understood.
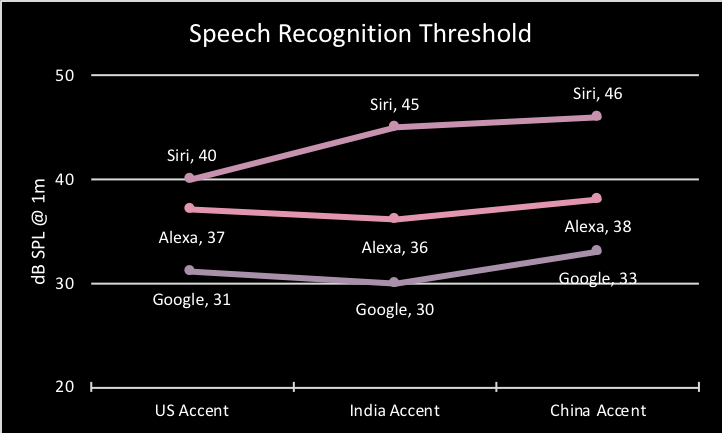
SRT Observations
Alexa and Google maximum ranges are 1dB and 2dB, respectively. This indicates that accented speech has a minimal impact on speech recognition threshold. Siri’s maximum range is 6dB, and for this evaluation, we consider anything greater than 5dB as significant. This suggests that people with a Chinese accent may have to intentionally speak louder to be understood by Siri.
Speech In Noise (SIN)
The SIN evaluation introduces background noise, which is challenging for both humans and speech recognition systems. The background noise types used are babble and pink noise, which are meant to be representative of real-world environments. Each smart speaker is tasked with recognizing several key words in spoken sentences. The sentences are accompanied with a background noise signal which starts out very low and is gradually raised as the test progresses. This test is modeled after a SIN test which is commonly used to check human hearing. Thus, the end results can be mapped directly to human performance levels associated with hearing loss (normal, mild, moderate, severe). The numbers presented are in terms of signal-to-noise-ratio loss (SNR Loss) which represents performance in noise as compared to a normal hearing person. For example, an SNR Loss value of 0-3 indicates that the device is 0-3dB away from a normal-hearing persons’ performance in noise. Alternatively, a SNR Loss of >15dB indicates the device is greater than 15dB away from a normal hearing human and this is categorized as severe hearing loss. For this evaluation a lower number is better.
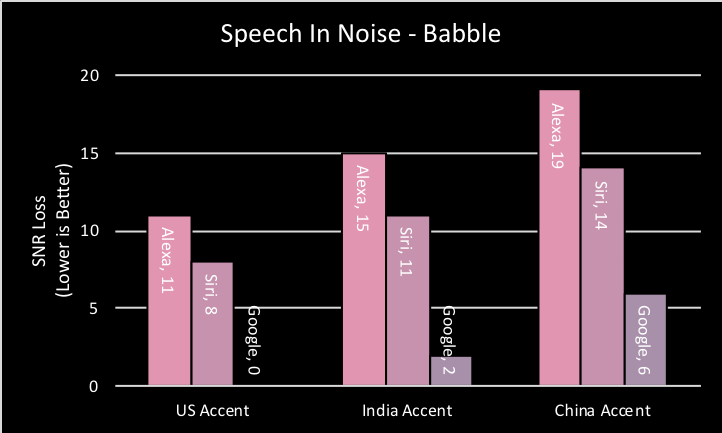
SIN Observations
With US-accent, both Alexa and Siri performed in the range of moderate hearing loss. The Google device fared better with US-accent and scored within the normal hearing range. Moving on to India-accent we see a slight degradation with both Alexa and Siri, but both are still within the range of moderate loss. Google also shows a slight degradation, but is still within the normal hearing range. Finally, with China-accent each device encounters an additional challenge. The Alexa device enters the severe loss category. Siri’s value gets larger, but still remains in the moderate window. Google now exhibits mild loss.
About Accented Speech
The accented speech datasets used in this evaluation were created by people born in, raised and currently living in each respective country. For example, the accented speech for China was created by a person born/living in China, but also fluent in English. The same applies for US and India datasets. For this evaluation we wanted to use accents that were easily perceived by a native US listener and not so harsh that normal hearing humans could not understand the spoken words/sentences. It is well understood that the level of accent significantly varies from person to person. As such, we required method to quantify the ‘degrees of nativeness’ or ‘level of accent’ for each dataset. To accomplish this, we contracted the expertise of SRI International and its Speech Technology and Research Laboratory.
Using their EduSpeak™ toolkit, the SRI team analyzed and categorized the vocalize.ai datasets on a scale of 1 to 6. On this scale, a score near 5 corresponds to native or near-native performance and score near 1 indicates a very strong and very hard to understand accent. A moderate accent that is understandable would score near 3. Scores of 2 and 4 fall in between the corresponding categories. The results are listed here:
- English with US accent 5.3 (native, near native)
- English with Indian accent 3.7 (moderate accent)
- English with Chinese accent 3.2 (moderate accent)
Additional Datasets
Evaluations are ongoing and additional accent datasets for Mexico and Korea are being evaluated now. US youth speech is also under evaluation. Those results will be shared on request. In the future, we will create additional datasets to represent stronger accents scoring closer to 1 or 2 on the EduSpeak™ scale.
Conclusions
The future is bright for conversational computing and the voice first-generation. Nevertheless, there are challenges unique to voice which need to be addressed. Vocalize.ai has demonstrated how accented speech degrades the performance of the most popular smart speakers on the market. The results of this evaluation are really just the tip of the iceberg. Developing new tools, driving consensus and expanding datasets are all critical for ensuring speech recognition works well for everyone, regardless of gender, age or accent.
About Vocalize.ai
Measuring the performance of automatic speech recognition (ASR) and natural language understanding (NLU) is the initial focus of Vocalize.ai. Over the last 12 months, we have been methodically developing an approach and creating tools to support our goals. Throughout the year, we have shared preliminary test results on smart speakers and the usual suspects Google, Alex and Siri. However, our mission is much broader than just smart speakers.
Our mission: Create tools and procedures designed to audit and interrogate AI systems. Tools that quantify performance and identify gaps related to bias. Drive consensus and sharing of results, enabling humans to trust in AI services.
Contact Info
If you would like more information on any of our services, or just want to discuss the voice first future, we would love to hear from you.
dev@vocalize.ai